确定数据结构
首先,明确一个问题:要存什么。
以下是我最终代码的数据结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| {
"time": "2022-08-04 10:25:07",
"pages": 3,
"posts": [
{
"page": 1,
"posts": [
{
"title": "历史学习记录",
"post_time": "2022-08-04 03:37:49",
"author_id": "潘妮sun",
"url": "http://bbs.tianya.cn/post-170-917565-1.shtml",
"author_url": "http://www.tianya.cn/112795571",
"read_num": "8",
"reply_num": "4",
"content": "黄帝和炎帝其实并不是皇帝,而是古书记载中黄河流域远古..."
},
......
]
}
]
}
|
由此可见,我们要存的东西如下:
- 爬取时间,页数
- 帖子标题&链接
- 帖子发送时间
- 帖子作者&链接
- 阅读数&回复数
- 帖子内容
页面分析
目录页面分析
打开目标页面:http://bbs.tianya.cn/list.jsp?item=170
按下f12,打开开发者工具,分析页面结构。
主体页面由9个tbody构成,其中第一个为表格标题,其余八个内部各有10个帖子,共80个
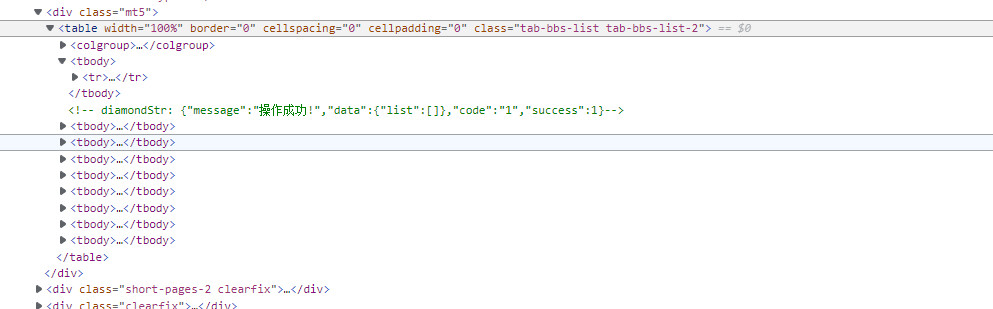
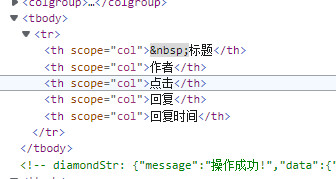
每个tbody内由10个tr构成,记录了帖名和链接、作者和链接、点击量、回复量、最后回复时间

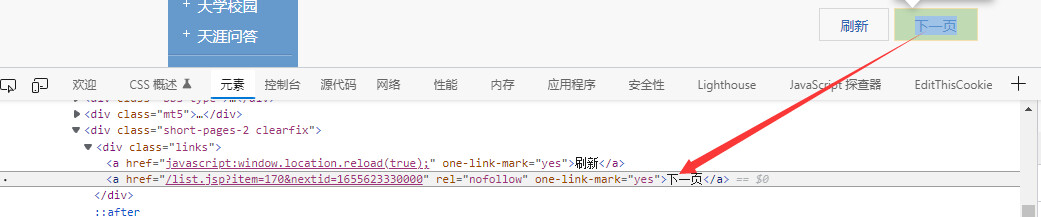
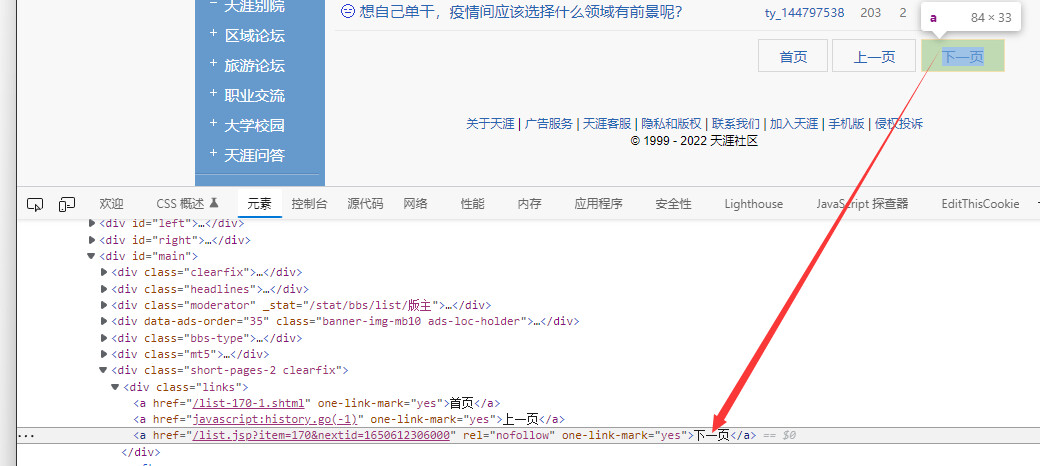
每页最后会有一个链接指向下一页,如同链表的指针
这里注意,第一页的下一页按钮是第二个,其余页是第三个
帖子页面分析
随便打开一条帖子, 如http://bbs.tianya.cn/post-170-878768-1.shtml
按下f12,打开开发者工具,分析页面结构。
html的head标签内有文章题目(后面会提到为啥要说这个)
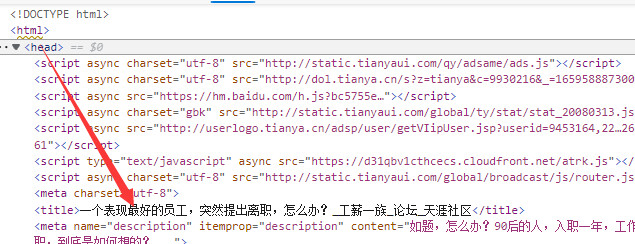
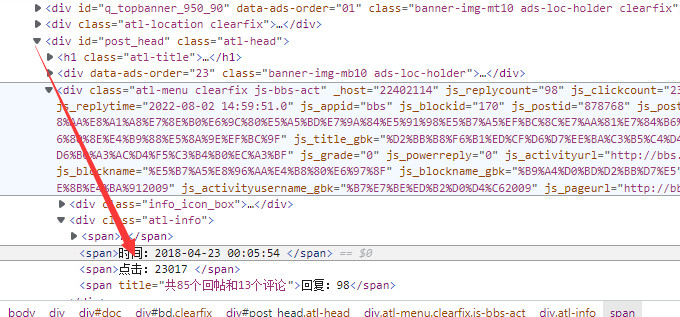
发帖时间有两种
一种为div内单独span标签内,依纯文本形式存储
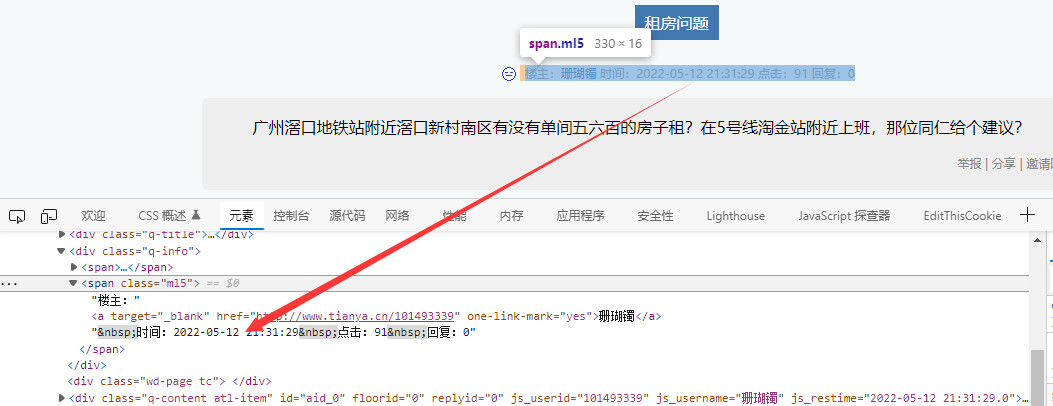
另一种为和点击和回复一起整体保存
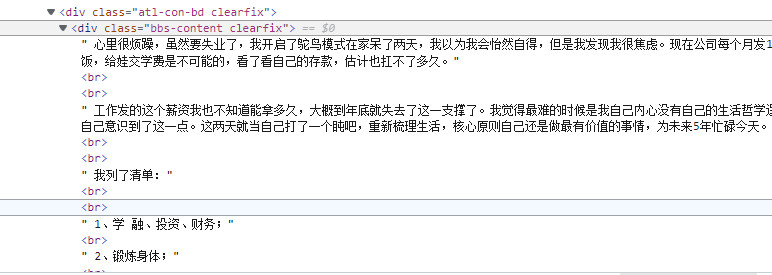
帖子内容保存在”bbs-content”的div里,以<br>分段
确定工具
爬取html这里选用request库
解析提取html这里选用xpath库
文本格式化存储要用到json库
记录时间要用到time库
提取文本数据可能要用到正则表达式,导入re库(可选)
*注: 这里可以先记录下浏览器的User-Agent, 构造headers
1
2
3
| headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.49'
}
|
开始提取
提取页面
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| import requests
from lxml import etree
url = ‘http://bbs.tianya.cn/list.jsp?item=170’
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.49'
}
posts = []
next = ‘’
raw = requests.get(url, headers=headers)
html = etree.HTML(raw.text)
next = "http://bbs.tianya.cn" + html.xpath('//*[@id="main"]/div[@class="short-pages-2 clearfix"]/div/a[2]/@href')[0]
if html.xpath('//*[@id="main"]/div[@class="short-pages-2 clearfix"]/div/a[2]/text()')[0] != '下一页':
next = "http://bbs.tianya.cn" + html.xpath('//*[@id="main"]/div[@class="short-pages-2 clearfix"]/div/a[3]/@href')[0]
tbodys = html.xpath('//*[@id="main"]/div[@class="mt5"]/table/tbody')
tbodys.remove(tbodys[0])
for tbody in tbodys:
items = tbody.xpath("./tr")
for item in items:
title = item.xpath("./td[1]/a/text()")[0].replace('\r', '').replace('\n', '').replace('\t', '')
post_url = "http://bbs.tianya.cn" + item.xpath("./td[1]/a/@href")[0]
author_id = item.xpath("./td[2]/a/text()")[0]
author_url = item.xpath("./td[2]/a/@href")[0]
read_num = item.xpath("./td[3]/text()")[0]
reply_num = item.xpath("./td[4]/text()")[0]
post = {
'title': title,
'author_id': author_id,
'url': post_url,
'author_url': author_url,
'read_num': read_num,
'reply_num': reply_num,
}
posts.append(post)
print(post)
|
提取单个帖子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| post_time = ''
post_content = ''
post_url = ‘http://bbs.tianya.cn/post-170-917511-1.shtml’
postraw = requests.get(posturl, headers=headers)
posthtml = etree.HTML(postraw.text)
try:
posttimeraw = posthtml.xpath('//*[@id="post_head"]/div[2]/div[2]/span[2]/text()')[0]
except:
posttimeraw = posthtml.xpath('//*[@id="container"]/div[2]/div[3]/span[2]/text()[2]')[0]
post_time = re.findall(r'\d+-\d+-\d+ \d+:\d+:\d+', posttimeraw)[0]
if len(title) == 0:
title = posthtml.xpath('/html/head/title/text()')[0].replace('_工薪一族_论坛_天涯社区', '')
contents = posthtml.xpath('//*[@id="bd"]/div[4]/div[1]/div/div[2]/div[1]/text()')
post_content = ''
for string in contents:
string = string.replace('\r', '').replace('\n', '').replace('\t', '').replace('\u3000', '') + '\n'
post_content += string
|
构造函数
这里的目的是为了拼接单帖和页面代码,实现单页内全部数据的提取(包括题目,内容和数据)
下文为我的实现函数,入参为页面网址url和headers,出参为构造的单页面所有数据构成的列表posts和下一页的链接next
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
| def get_posts(url, headers):
raw = requests.get(url, headers=headers)
code = raw.status_code
posts = []
next = ''
if code == 200:
html = etree.HTML(raw.text)
next = "http://bbs.tianya.cn" + html.xpath('//*[@id="main"]/div[@class="short-pages-2 clearfix"]/div/a[2]/@href')[0]
if html.xpath('//*[@id="main"]/div[@class="short-pages-2 clearfix"]/div/a[2]/text()')[0] != '下一页':
next = "http://bbs.tianya.cn" + html.xpath('//*[@id="main"]/div[@class="short-pages-2 clearfix"]/div/a[3]/@href')[0]
tbodys = html.xpath('//*[@id="main"]/div[@class="mt5"]/table/tbody')
tbodys.remove(tbodys[0])
for tbody in tbodys:
items = tbody.xpath("./tr")
for item in items:
title = item.xpath("./td[1]/a/text()")[0].replace('\r', '').replace('\n', '').replace('\t', '')
url = "http://bbs.tianya.cn" + item.xpath("./td[1]/a/@href")[0]
author_id = item.xpath("./td[2]/a/text()")[0]
author_url = item.xpath("./td[2]/a/@href")[0]
read_num = item.xpath("./td[3]/text()")[0]
reply_num = item.xpath("./td[4]/text()")[0]
postraw = requests.get(url, headers=headers)
postcode = postraw.status_code
if postcode == 200:
posthtml = etree.HTML(postraw.text)
try:
posttimeraw = posthtml.xpath('//*[@id="post_head"]/div[2]/div[2]/span[2]/text()')[0]
except:
posttimeraw = posthtml.xpath('//*[@id="container"]/div[2]/div[3]/span[2]/text()[2]')[0]
post_time = re.findall(r'\d+-\d+-\d+ \d+:\d+:\d+', posttimeraw)[0]
if len(title) == 0:
title = posthtml.xpath('/html/head/title/text()')[0].replace('_工薪一族_论坛_天涯社区', '')
contents = posthtml.xpath('//*[@id="bd"]/div[4]/div[1]/div/div[2]/div[1]/text()')
post_content = ''
for string in contents:
string = string.replace('\r', '').replace('\n', '').replace('\t', '').replace('\u3000', '') + '\n'
post_content += string
post = {
'title': title,
'post_time': post_time,
'author_id': author_id,
'url': url,
'author_url': author_url,
'read_num': read_num,
'reply_num': reply_num,
'content': post_content
}
posts.append(post)
print(title)
return posts, next
|
保存数据
本项目标:构造主函数,实现json格式化保存
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| def main():
url = 'http://bbs.tianya.cn/list.jsp?item=170'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.49'
}
postss = {
'time': time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()),
'pages': 0,
'posts': []
}
for i in range(3):
print("page: " + str(i + 1))
posts, next = get_posts(url, headers)
pages = {
'page': i + 1,
'posts': posts
}
postss['posts'].append(pages)
url = next
postss['pages'] += 1
with open('tianya.json', 'w', encoding='utf-8') as f:
json.dump(postss, f, ensure_ascii=False, indent=4)
with open('tianya.json', 'w', encoding='utf-8') as f:
json.dump(postss, f, ensure_ascii=False, indent=4)
|
注意事项
直接从页面提取文本标题会有一些干扰符号,需要去除

页面中部分标题有特殊样式,无法提取,需要进入该帖后利用head中的题目提取存入
成品代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
| import requests
from lxml import etree
import json
import re
import time
def get_posts(url, headers):
raw = requests.get(url, headers=headers)
code = raw.status_code
posts = []
next = ''
if code == 200:
html = etree.HTML(raw.text)
next = "http://bbs.tianya.cn" + html.xpath('//*[@id="main"]/div[@class="short-pages-2 clearfix"]/div/a[2]/@href')[0]
if html.xpath('//*[@id="main"]/div[@class="short-pages-2 clearfix"]/div/a[2]/text()')[0] != '下一页':
next = "http://bbs.tianya.cn" + html.xpath('//*[@id="main"]/div[@class="short-pages-2 clearfix"]/div/a[3]/@href')[0]
tbodys = html.xpath('//*[@id="main"]/div[@class="mt5"]/table/tbody')
tbodys.remove(tbodys[0])
for tbody in tbodys:
items = tbody.xpath("./tr")
for item in items:
title = item.xpath("./td[1]/a/text()")[0].replace('\r', '').replace('\n', '').replace('\t', '')
url = "http://bbs.tianya.cn" + item.xpath("./td[1]/a/@href")[0]
author_id = item.xpath("./td[2]/a/text()")[0]
author_url = item.xpath("./td[2]/a/@href")[0]
read_num = item.xpath("./td[3]/text()")[0]
reply_num = item.xpath("./td[4]/text()")[0]
postraw = requests.get(url, headers=headers)
postcode = postraw.status_code
if postcode == 200:
posthtml = etree.HTML(postraw.text)
try:
posttimeraw = posthtml.xpath('//*[@id="post_head"]/div[2]/div[2]/span[2]/text()')[0]
except:
posttimeraw = posthtml.xpath('//*[@id="container"]/div[2]/div[3]/span[2]/text()[2]')[0]
post_time = re.findall(r'\d+-\d+-\d+ \d+:\d+:\d+', posttimeraw)[0]
if len(title) == 0:
title = posthtml.xpath('/html/head/title/text()')[0].replace('_工薪一族_论坛_天涯社区', '')
contents = posthtml.xpath('//*[@id="bd"]/div[4]/div[1]/div/div[2]/div[1]/text()')
post_content = ''
for string in contents:
string = string.replace('\r', '').replace('\n', '').replace('\t', '').replace('\u3000', '') + '\n'
post_content += string
post = {
'title': title,
'post_time': post_time,
'author_id': author_id,
'url': url,
'author_url': author_url,
'read_num': read_num,
'reply_num': reply_num,
'content': post_content
}
posts.append(post)
print(title)
return posts, next
def main():
url = 'http://bbs.tianya.cn/list.jsp?item=170'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.49'
}
postss = {
'time': time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()),
'pages': 0,
'posts': []
}
for i in range(3):
print("page: " + str(i + 1))
posts, next = get_posts(url, headers)
pages = {
'page': i + 1,
'posts': posts
}
postss['posts'].append(pages)
url = next
postss['pages'] += 1
with open('tianya.json', 'w', encoding='utf-8') as f:
json.dump(postss, f, ensure_ascii=False, indent=4)
with open('tianya.json', 'w', encoding='utf-8') as f:
json.dump(postss, f, ensure_ascii=False, indent=4)
if __name__ == '__main__':
main()
|
